GPT3.51 - 论文精读学习笔记
Fine-Tuning Language Models from Human Preferences
标签:Basic Architectures of LLMs论文链接:Fine-Tuning Language Models from Human Preferences
官方项目/代码:lm-human-preferences
代码:知乎博文代码
You are what you eat.
And I'm cooking what I eat! :)
目录
GPT3.5 - 论文精读学习笔记背景RLHF在LLM时代的重要性和亮点引言全文梗概摘要解读本文方案预训练模型细节微调细节数据集在线数据采集实验结果参考与补充开源工具 for RLHF补充想法参考博文原文目录
提前说明:本系列博文主要是对参考博文的解读与重述(对重点信息进行标记、或者整段摘录加深自己的记忆和理解、融合多个博文的精髓、统合不同的代表性的案例),仅做学习记录笔记使用。与君共享,希望一同进步。
背景
题目的翻译:基于人类偏好微调语言模型
RLHF在LLM时代的重要性和亮点
Reinforcement Learning from Human Feedback, RLHF
大型语言模型LLM近年来在根据人类提示生成多样文本上取得巨大成功,但衡量“好”文本仍然是个挑战,因为这涉及主观判断和情境依赖性。传统训练方法如预测下一个词(例如交叉熵)有其局限性,而标准指标如BLEU和ROUGE仅提供简单的文本比对。这里就是从人类反馈中学习的强化学习(RLHF)的重要性所在:它透过直接利用人类反馈来优化模型,使得大型语言模型不仅适应广泛文本资料,还能对齐人类复杂价值观,为语言模型的发展开启新的可能性。
RLHF在LLM微调中的角色与重要性
RLHF将人类判断转化为奖励学习,这使得可以将强化学习应用于以人类判断为基准的复杂任务。
在自然语言处理领域,RLHF利用人类偏好训练出的奖励模型对语言模型进行微调,这个过程超越了纯粹的监督学习,让模型更接近人类的使用和理解方式。
RLHF特别适用于没有充足监督资料集的NLP任务,或者当现成的程序化奖励函数不足以作为真实目标的良好代理时。
研究亮点
在
风格化续写任务中,使用5k个人类比较就能达到良好的结果,微调模型被人类选择的频率达到86%,优于无微调的模型(zero-shot)和监督学习微调的情感网络。在
摘要任务中,用60k 个人类样本训练的模型能够像“聪明的复制机”一样工作,它们通常从输入文章中复制整句,但会变化复制内容以跳过不相关的前言,这种行为自然地从资料收集和训练过程中产生,没有使用任何明确的复制机制。
OpenAI提供的ChatGPT练成过程可以看到人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)训练的三步骤:
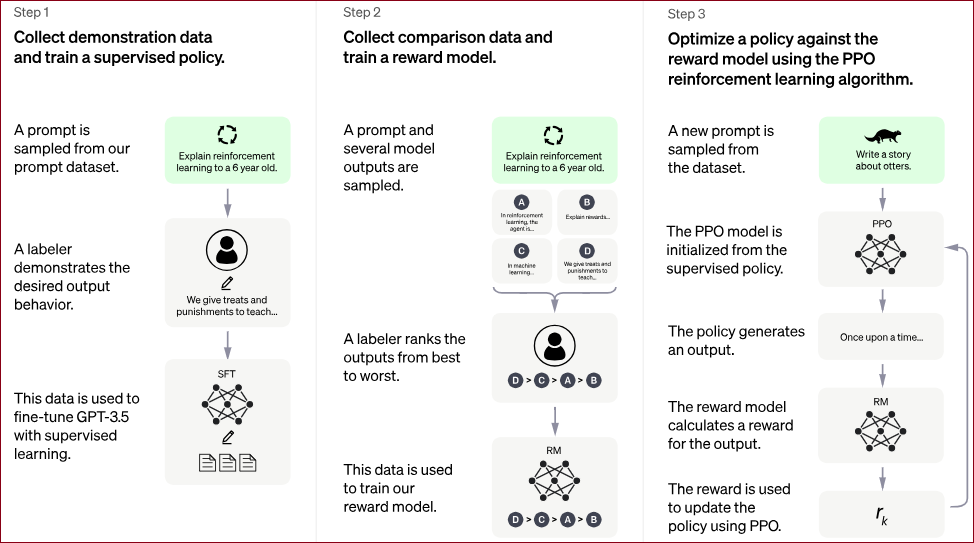
Step1:收集示范资料并训练监督式策略(Supervised Policy)
从提示资料集中抽取一个提示。
标注者展示了期望的输出行为。
利用这些资料对GPT-3.5进行监督学习的微调。
Step2:收集比较资料并训练奖励模型(Reward Model)
抽取一个提示和几个模型输出作为样本。
标注者对这些输出从最好到最差进行排名。
使用这些资料来训练奖励模型。
Step3:使用PPO(Proximal Policy Optimization)强化学习算法根据奖励模型优化策略。
从资料集中抽取一个新的提示。
PPO模型从监督式策略初始化。
策略生成一个输出。
奖励模型为输出计算奖励。
使用PPO根据奖励更新策略。
预训练 + 人类偏好:OpenAI 19年出的文章,将自然语言处理的模型预训练与人类偏好学习相结合,该文章的思路是当前火热的 RLHF 的雏形方案。
奖励学习使强化学习(RL)能够应用于由人类判断定义奖励的任务,通过向人类提问建立奖励模型。
大多数关于奖励学习的工作都使用了模拟环境,但关于价值观的复杂信息通常用自然语言表达,本文认为语言的奖励学习是使RL在现实世界任务中实用和安全的关键。
当agent必须与人类进行通信以帮助提供更准确的监督信号时,自然语言尤为重要。
之前也有很多的方法将强化学习应用于自然语言任务
当前已有的奖励函数定义形式:
用于翻译的BLEU
用于摘要的ROUGE
用于故事生成的事件检测器等
对于翻译任务,使用off-policy来基于人工评测作为奖励
本文使用一个根据人类对文本补全任务的偏好训练的奖励模型来作为奖励函数。
引言
我们希望将强化学习应用于那些仅通过人类判断来定义的复杂任务,在这些任务中,只有通过询问人类才能判断结果的好坏【1. 目的】。为此,我们可以1 首先使用人类标签来训练一个奖励模型,2 然后优化该模型。尽管有大量通过与人类互动来学习此类模型的研究,但这些研究直到最近才被应用于现代深度学习,并且即便如此,也仅应用于相对简单的模拟环境(Christiano等,2017;Ibarz等,2018;Bahdanau等,2018)。相比之下,在现实世界中,人类需要向AI代理指定复杂目标,这可能涉及并需要自然语言,这是表达价值观念的丰富媒介。当代理必须与人类进行交流以提供更准确的监督信号时,自然语言尤为重要(Irving等,2018;Christiano等,2018;Leike等,2018)。 自然语言处理最近取得了显著进展。一种成功的方法是先在无监督数据集上预训练一个大型生成语言模型,然后对该模型进行监督任务的微调【2.做法与对比】(Dai和Le,2015;Peters等,2018;Radford等,2018;Khandelwal等,2019)。这种方法通常显著优于从头开始训练监督数据集,并且一个单一的预训练语言模型通常可以通过微调在许多不同的监督数据集上达到最先进的性能【3. 做法的优势】(Howard和Ruder,2018)。在某些情况下,不需要微调:Radford等(2019)发现,经过生成训练的模型在无需额外训练的情况下(零样本)在NLP任务上表现良好。 将强化学习应用于自然语言任务有着悠久的历史。许多这方面的工作使用算法定义的奖励函数,例如翻译的BLEU(Ranzato等,2015;Wu等,2016)、摘要的ROUGE(Ranzato等,2015;Paulus等,2017;Wu和Hu,2018;Gao等,2019b)、基于音乐理论的奖励(Jaques等,2017)或故事生成的事件检测器(Tambwekar等,2018)。Nguyen等(2017)在BLEU上使用了RL,但应用了几个错误模型来模拟人类行为。Wu和Hu(2018)和Cho等(2019)从现有文本中学习连贯性模型,并将其用作摘要和长文生成的RL奖励。Gao等(2019a)通过将奖励学习应用于一篇文章一次构建了一个交互式摘要工具。使用人类评价作为奖励的实验包括Kreutzer等(2018),他们使用离线策略奖励学习进行翻译,以及Jaques等(2019),他们将Jaques等(2017)的修改版Q学习方法应用于对话中的隐式人类偏好。Yi等(2019)从人类那里学习奖励以微调对话模型,但对奖励进行了平滑处理以允许监督学习。我们参考Luketina等(2019)对涉及语言作为组件的RL任务和使用迁移学习进行RL结果的调查。
在本文中,我们结合了自然语言处理中的预训练进展和人类偏好学习。我们使用从人类偏好中训练的奖励模型,通过强化学习而不是监督学习来微调预训练的语言模型。根据Jaques等(2017;2019)的研究,我们使用KL约束来防止微调模型偏离预训练模型。我们将我们的方法应用于两类任务:以匹配目标风格(如正面情感或生动描述性语言)的方式继续文本,以及对CNN/Daily Mail或TL;DR数据集(Hermann等,2015;Völske等,2017)中的文本进行摘要。我们的动机是处理那些没有或不足的监督数据集的NLP任务,以及那些程序化奖励函数是我们真实目标的糟糕代理的任务。
对于风格化续写任务,我们使用5,000个人类比较(每次选择4个续写中的最佳一个)进行微调,使得微调后的模型在86%的情况下被人类更喜欢,而对比零样本学习为77%,对比监督学习的情感网络为77%【体现出无监督预训练+微调的效果更好】。
对于摘要任务,我们使用60,000个人类样本来训练模型,这些模型可以大致描述为“智能复制器”:它们通常从输入中复制整句话,但会跳过不相关的开头。这种复制行为自然地从数据收集和训练过程中出现;我们没有使用任何显式的复制机制(如See等,2017;Gehrmann等,2018)。一种解释是,复制是一种容易准确的方式,因为我们没有指示标签者惩罚复制,而是指示他们惩罚不准确。它还可能反映了一些标签者检查复制作为快速确保摘要准确性的一种启发式方法。确实,人类标签者显著更喜欢我们的模型而不是监督微调的基线,甚至比人类编写的参考摘要还要喜欢,但不如复制前三句话的基线 【好处:这种行为(跳过不相干部分)并不是通过显式的复制机制实现的,而是在数据收集和训练过程中自然出现的】。
启发 这里 ↑ 有点意思,可以深入看看!
对于摘要任务,我们继续收集额外数据,并在策略改进时重新训练我们的奖励模型(在线数据收集)。我们还测试了离线数据收集,使用原始语言模型的数据来训练奖励模型;离线数据收集显著降低了训练过程的复杂性。对于TL;DR数据集,人类标签者71%的时间更喜欢在线数据收集训练的策略,而在定性评估中,离线模型通常提供不准确的摘要。相比之下,对于风格化续写任务,我们发现离线数据收集效果同样好。这可能与风格任务所需的数据非常少有关;Radford等(2017)显示,生成训练的模型可以从很少的标签样本中学习分类情感。
在并行工作中,Böhm等(2019)也使用人类评估来学习摘要的奖励函数,并使用RL优化该奖励函数。他们的工作更详细地调查了CNN/Daily Mail数据集上学习的策略和奖励函数,而我们更广泛地探索了从人类反馈中学习,并在更大的计算规模上进行探索。因此,我们考虑了几个额外的任务,探索了在线奖励模型训练和更多数据的效果,并对大规模语言模型进行了奖励建模和RL微调。
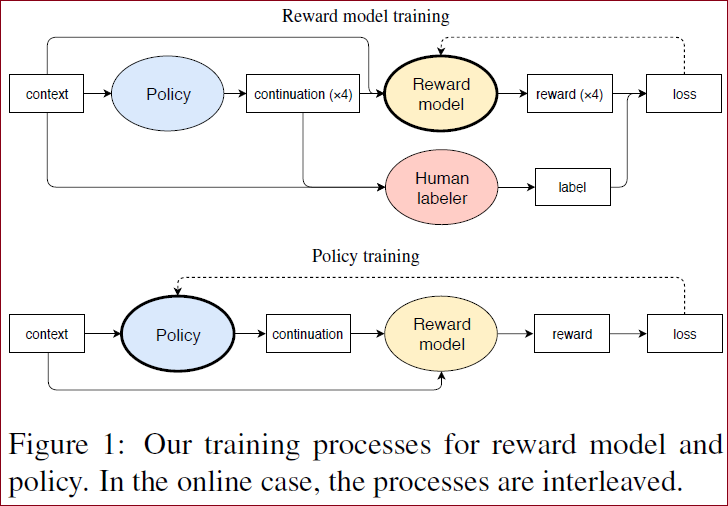
1 奖励模型增强强化学习对任务处理的过程
奖励模型训练
Context(上下文):从上下文开始,这里指输入的一段文字或语境;
Policy(策略):基于上下文生成多个(例如四个)可能的续写(continuation);
Human Labeler(人类标签者):这些生成的续写被送给人类标签者,人类根据自己的判断对这些续写进行评分或选择最好的续写;
Reward Model(奖励模型):人类标签者的选择结果被用于训练奖励模型。奖励模型根据人类的反馈生成对应的奖励信号;
Loss(损失):奖励模型根据生成的奖励信号计算损失,并通过优化过程不断改进自身。
策略训练
Context(上下文):同样从上下文开始。
Policy(策略):基于上下文生成续写。
Reward Model(奖励模型):使用训练好的奖励模型对生成的续写进行评估,生成奖励信号。
Loss(损失):策略模型根据奖励信号计算损失,并通过优化过程不断改进策略。
在在线情况下,这两个过程是交替进行的,也就是说,奖励模型和策略会不断地互相优化,形成一个循环。【优化点】
2 好处
奖励模型和策略模型在互相优化的过程中,策略模型会逐渐生成更符合人类偏好的回答,奖励模型也会越来越准确地评估这些回答。【不断优化回答,使其适应上下文环境进行有效反馈】
3 举例
奖励模型训练
Context(上下文):输入:“你好!今天的天气怎么样?”Policy(策略):生成四个可能的续写:续写1:“天气很好,适合外出。”
续写2:“我不知道,你可以看看天气预报。”
续写3:“今天天气晴朗,温度适中。”
续写4:“今天可能会下雨,记得带伞。”
Human Labeler(人类标签者):人类标签者选择最好的续写。假设他们选择续写3:“今天天气晴朗,温度适中。”Reward Model(奖励模型):人类标签者的选择结果(续写3)用于训练奖励模型。奖励模型根据这个选择生成对应的奖励信号,例如给续写3一个高分。Loss(损失):奖励模型计算生成的奖励信号与实际选择的偏差,并通过优化过程不断改进自身。
策略训练
Context(上下文):再次输入:“你好!今天天气怎么样?”Policy(策略):策略模型基于上下文生成一个续写。例如,生成:“今天天气晴朗,适合外出。”Reward Model(奖励模型):使用训练好的奖励模型对生成的续写进行评估,假设奖励模型给这个续写打了高分,因为它符合之前人类选择的标准。Loss(损失):策略模型根据奖励信息计算损失,并通过优化过程改进策略,使其更倾向于生成高质量的续写。
4 引言核心内容
研究动机:希望将强化学习应用于复杂任务 【自然语言】,这些任务仅通过人类判断来定义,且需要自然语言来表达复杂的价值概念。
现状分析:虽然之前有大量研究通过与人类互动来学习模型,但这些研究主要应用于简单的模拟环境。现代深度学习下的奖励学习仍然主要集中在相对简单的环境中 【自然语言和模拟环境经过奖励学习的比较】。
自然语言处理的进展:预训练大型生成语言模型,然后对其进行监督任务的微调,这种方法在许多监督数据集上表现优异,甚至在某些情况下无需微调即可在NLP任务中表现良好。
强化学习在自然语言任务中的应用:过去的工作主要使用算法定义的奖励函数,但本文结合了自然语言处理中的预训练进展和人类偏好学习,通过奖励模型进行强化学习微调。
总的来说, 提出了一种新的方法,将人类偏好与预训练语言模型相结合,通过强化学习进行微调,以解决自然语言处理中的复杂任务。这种方法特别适用于没有或不足的监督数据集,以及那些程序化奖励函数不充分的任务。
全文梗概
摘要解读
奖励学习使得强化学习(RL)可以应用于那些通过人类判断来定义奖励【1. 关键词是什么】 的任务,通过向人类提问来建立奖励模型。大多数关于奖励学习的研究使用了模拟环境,但复杂的价值信息通常以自然语言表达【2. 对比】,我们认为将奖励学习应用于语言是使RL在实际任务中实用且安全的关键。在本文中,我们基于生成预训练语言模型的进展,将奖励学习应用于四个自然语言任务:继续生成正面情感文本或物理描述性语言,以及TL;DR和CNN/Daily Mail数据集上的摘要任务【3. 任务】。对于风格化续写任务,我们仅通过5000次人类比较就取得了良好结果。对于摘要任务,通过60,000次人类比较训练的模型能够复制整句话但跳过不相关的前言;这导致合理的ROUGE分数和人类标签者的优异表现,但可能利用了标签者依赖简单启发式的事实 【4. 实验结果】。
奖励学习:通过人类的反馈来定义奖励,从而指导强化学习(RL);
模拟环境:之前的研究主要在虚拟环境中进行,但这些环境往往过于简单,无法反映现实世界的复杂性。比如:选择最短的路径通关游戏,相比于自然语言,复杂度相差甚远。
主要任务:奖励模型使得强化学习在处理任务更有效。指的是自然语言那类任务。
实验结果:
风格化续写:仅通过5000次人类比较就取得了良好结果,这表明人类反馈在指导模型生成方面非常有效。
摘要任务:通过60,000次人类比较训练的模型能够生成合理的摘要,尽管这种方法可能依赖了人类标签者使用简单启发式的事实。
本文方案
本文在语言模型生成预训练的基础上,将奖励学习应用于四个自然语言任务(主要是文本续写和文本摘要):
使用积极情感进行文本续写
使用自然描述语言进行文本续写
数据集上的摘要任务
CNN / Daily Mail 数据集上的摘要任务
将自然语言处理的模型预训练与人类偏好学习相结合
使用根据人类对文本补全的偏好训练的奖励模型,通过强化学习而不是监督学习来微调预训练的语言模型
使用KL约束来防止微调后的模型偏离预训练的模型太远
本文工作的出发点
对于NLP任务,有监督数据集很难获取或者数据量很少
基于程序设计的奖励函数一般效果太差,难以实现准确的目标
本文方案结果
对于文本续写任务上的5000个对比样本,基于人工评测取得了不错的结果
人类评估方式:4个续写结果中选择最好的结果
与zero-shot模型相比,RL微调模型在86%情况下更被人类偏好
与有监督微调模型相比,RL微调模型在77%情况下更被人类偏好
对于文本摘要任务,在60000个样本对数据上训练的模型可以实现从输入文本中复制几个句子,并跳过不相干的前言,这种方式在 ROUGE 评分和让标注员进行人工评测结果上来看都不错,但是这里的人工评测不一定靠谱,因为标注员也更倾向于简单的评估方式,认为出现在原文中的摘要句子是好摘要(标注过程并没有让标注员对整段句子的复制进行惩罚,只让标注员惩罚不准确的摘要)
实现方式
词汇和语言模型
以一个预先训练好的语言模型为出发点,该模型能够预测文章序列的概率。
从一个词汇集
对于语言模型
以摘要任务为例,模型的输入一般是最多1000字的文章,输出 y 可以是一个100个词的摘要。
这个公式表示的是一个语言模型
具体来说:
这个乘积过程从序列的第一个token开始,计算第二个token出现在第一个token之后的条件机率,然后计算第三个token出现在前两个token之后的条件机率,以此类推,直到计算出最后一个token的条件机率。将所有这些条件机率相乘,就得到了整个序列出现的机率。
这种方法是建立在token序列是按照一定顺序依次生成的假设上的,每个token的生成只依赖于它前面的token。这就是语言模型如何利用过去的信息来预测下一个token(字词)的基础,并且是许多自然语言处理任务的核心,例如文章生成、机器翻译和语音识别。
任务应用
将语言模型
将该模型应用于输入空间
这个公式本质上是在问:在我们已经看到
策略初始化与微调
先给电脑一个基本指令集
初始化策略
这个公式描述的是期望奖励(expected reward)的计算方法,其中
但是在这里本文期望让模型更符合人类的评价,这需要通过询问人类来获得奖励。
本文首先基于人类标注来训练一个奖励模型,然后对奖励模型进行优化。
人类评估和奖励函数学习
利用人类评估来训练一个奖励函数,该函数评估生成文章的质量
根据Christinaniano等人的方法,通过让人类标注者选择对给定输入
其中,
这个损失函数
损失函数的目标是最小化模型对于选择最佳回答的不确定性。在这个公式中,我们寻找一个奖励函数
代码演示
x1import torch2import torch.nn as nn3def compute_loss(reward_model, x, y):4scores = reward_model(x)5exp_scores = torch.exp(scores)6sum_exp_scores = torch.sum(exp_scores, dim=1, keepdim=True)7softmax_probs = exp_scores / sum_exp_scores8# Gather the scores corresponding to the target classes9selected_score = scores.gather(1, y.view(-1, 1))10log_prob = torch.log(selected_score / sum_exp_scores)11# Compute the negative mean of the log probability as the loss12loss = -torch.mean(log_prob)1314return loss训练奖励模型
对于指定任务的输入
从四个输出
基于标注的数据训练奖励模型,奖励模型就是在
loss设计如下:
设计的思路是:让模型对于人类喜好的回答输出更高的奖励
微调奖励模型
损失函数帮助训练奖励模型,KL惩罚项
微调策略
这边的
代码演示
xxxxxxxxxx131def compute_reward(model, x, y):2# Calculate the log-probabilities of the Tuned Language Model's predictions3pi = tuned_model(x).log_softmax(dim=1)4# Calculate the log-probabilities of the reference distribution of Initial Language Model5rho = reference_model(x).log_softmax(dim=1)67# Calculate the KL divergence between pi and rho8kl_divergence = torch.sum(torch.exp(pi) * (pi - rho), dim=1)910# Calculate the reward using the modified reward function11reward = tuned_model(x).gather(1, y.view(-1, 1)) - beta * kl_divergence1213return reward强化学习训练
为了避免强化学习微调的模型
该项有熵加成的作用,防止policy偏移r有效范围太远;在风格文本续写任务下,这也是任务定义的重要组成部分:要求人类评估风格,但依靠KL散度来鼓励连贯性和话题性。
整体训练流程
使用强化学习算法(如PPO)对语言模型进行微调,以便根据奖励函数生成更优质的文章样本并定期重新训练奖励模型
包括从分布
收集人类标注数据。即,让标注员在模型输出的4个回答中挑选最好的回答;
基于预训练模型
使用 Proximal Policy Optimization(PPO) 进行强化学习训练;
对于在线数据收集的情况,继续收集额外的训练样本,并定期重新训练奖励模型
预训练模型细节
774M GPT-2模型,在WebText数据集上进行训练,36层,20个heads,embedding size 1280
对于风格续写任务,在BookCorpus数据集上进行有监督微调后再进行强化学习训练
为了提高样本质量,temperature对于所有实验都使用小于1的值
修改方式为将语言模型输出 logits 除以 T
惩罚项
摘说明核心概念部分
为了避免过度拟合,仅使用单一周期进行训练,并对不同任务采取统一的训练策略
为了避免训练时,模型不要偏离原始学习到的知识太远(梯度一次更新太大),论文中采用
惩罚项
如果
如果
clip函数将
当
反之,如果
即模型的行为比预期的要更接近原始模型,它没有充分利用学习过程中的自由度来优化或调整其策略。在这种情况下,我们可能希望模型探索更多新的行为,而不是严格地遵循原始模型的行为模式。
通过增加
这整个过程的目的是动态地调整惩罚项
微调细节
奖励模型训练
训练1个epoch避免过拟合
风格续写batchsize为8,摘要任务 batchsize为32
强化学习训练
使用PPO2的版本
2M个数据对用于训练,共4个epoch
风格续写batchsize为1024,摘要任务batchsize为512
用不同的种子和相同的KL惩罚
→ 为了解决这个问题,对于一些实验,文本使用对数空间比例控制器动态地改变
其中
xxxxxxxxxx161class AdaptiveKLController:2"""3Adaptive KL controller described in the paper:4https://arxiv.org/pdf/1909.08593.pdf5"""67def __init__(self, init_kl_coef, target, horizon):8self.value = init_kl_coef9self.target = target10self.horizon = horizon1112def update(self, current, n_steps):13target = self.target14proportional_error = np.clip(current / target - 1, -0.2, 0.2)15mult = 1 + proportional_error * n_steps / self.horizon16self.value *= mult
数据集
在线数据采集
如果训练后的策略
对于文本摘要任务在线数据采集很重要,简单的风格续写任务提升不大;
计算开启第
其中
实验结果
风格续写任务
摘要任务
参考与补充
Basics of Reinforcement Learning for LLMs
很好的说明强化学习在LLM定制化应用的基础,从不可微分的离散式奖励(经典的Q Learning)到连续的、基于梯度(可微分的)RLHF与PPO。
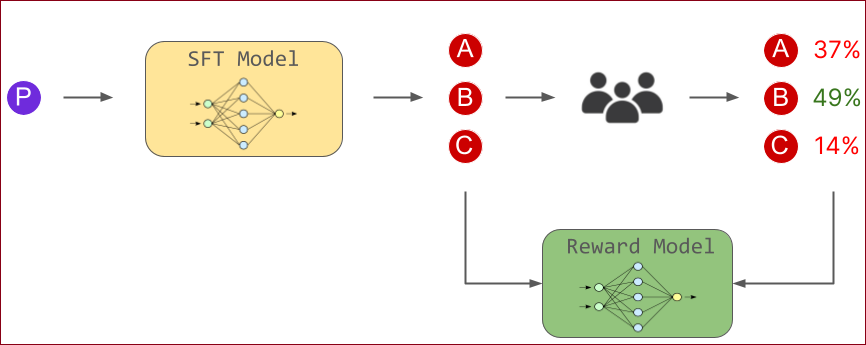
Illustrating Reinforcement Learning from Human Feedback (RLHF)
Step1. Pretraining language models
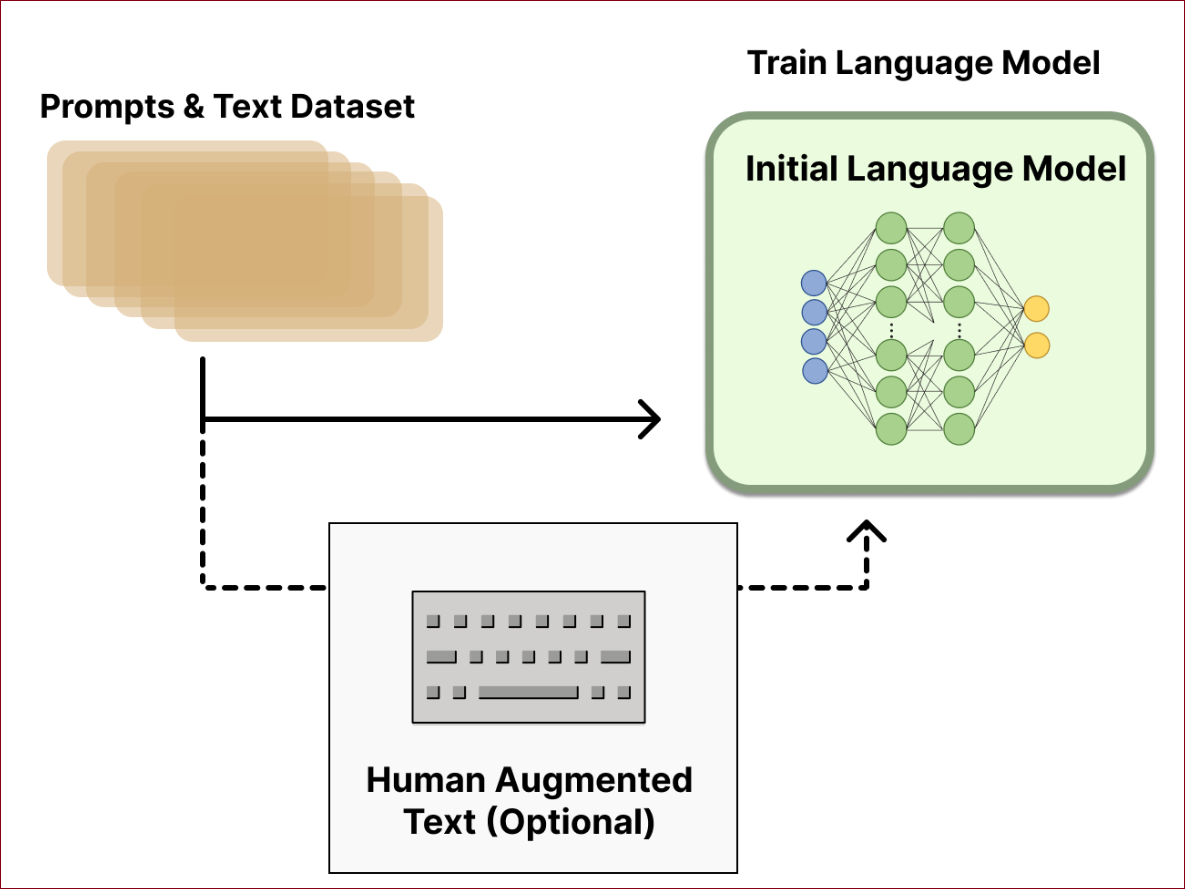
预训练语言模型(Pretraining language models)的过程包括以下步骤:
使用已训练的语言模型:RLHF作为起点使用一个已经过经典预训练目标预训练好的语言模型。
参数规模:OpenAI使用GPT-3的较小版本来建立其首个受欢迎的RLHF模型,InstructGPT。在共享的论文中,Anthropic使用了从1000万到520亿参数的转换模型(Transformer models)来进行这项任务。DeepMind记录使用了高达2800亿参数的模型Gopher。
可选的微调:这个初始模型还可以基于额外的文章或条件进行微调,但这不是必须的。例如,OpenAI在人类生成的“更受偏好”的文章上进行了微调,而Anthropic则通过将原始LM对照上下文线索进行蒸馏,产生了适合他们“有用、诚实和无害”标准的初始RLHF语言模型。
生成训练奖励模型的资料:需要生成资料来训练奖励模型,这是将人类偏好整合进系统的方式。
这个流程的核心是拥有一个对多样化指令反应良好的模型。目前还没有明确的答案说明“哪一个模型”是RLHF起点的最佳选择。
Step2. Reward model training
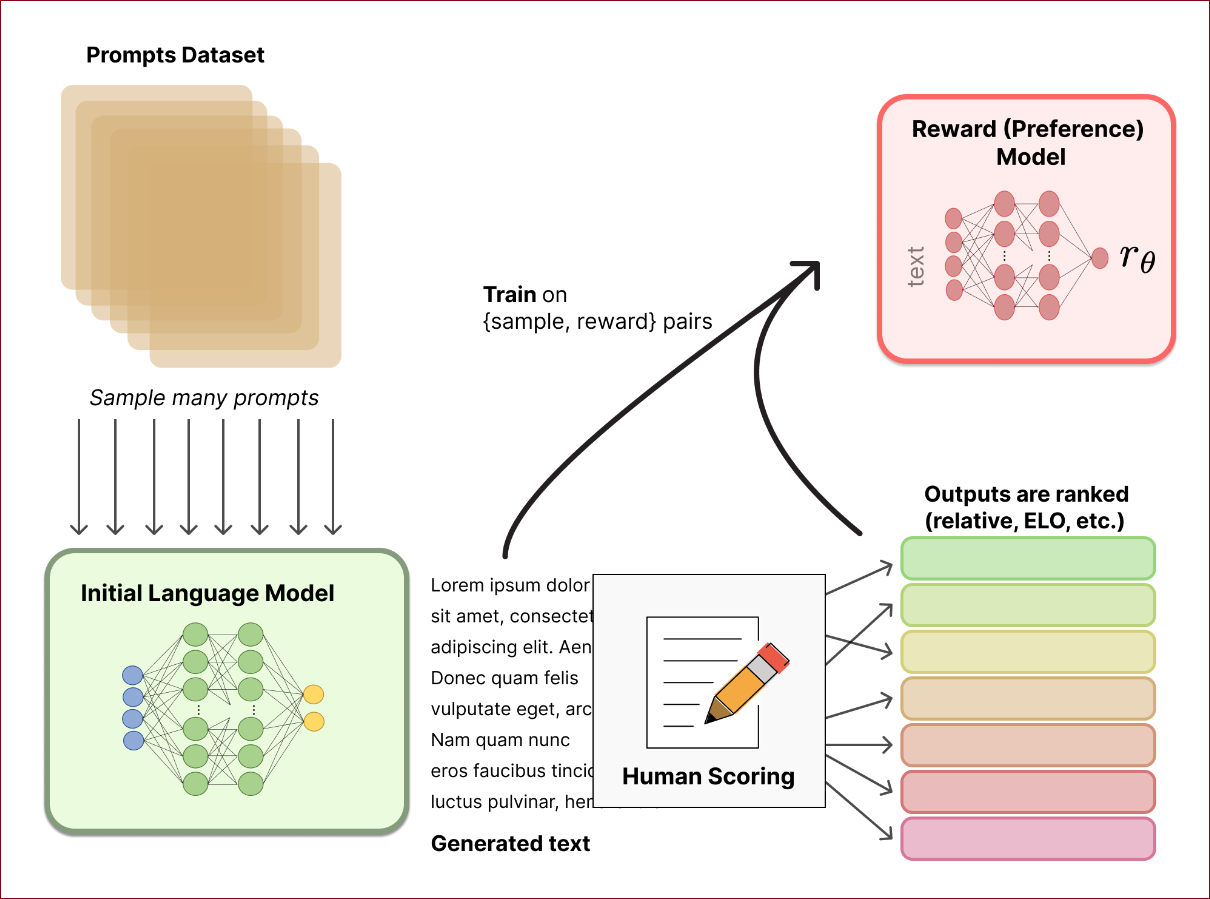
奖励训练模型(Reward Model Training)的概念与步骤如下:
奖励模型(RM,也称为偏好模型)的目的是建立一个模型,它能够接收一段文章序列,并返回一个标量奖励(scalar reward),这个奖励数值上代表人类的偏好。
「标量奖励」是指赋予代理(如人工智能模型)的数值,用以评估其在特定任务或情境中的表现。这个奖励通常是一个标量值,意味着它是一个单一数字而非一组数字或一个向量
在这过程中,使用初始语言模型生成文章,以及一个偏好模型给予评分,这个评分反映了人类对该文章的感知程度。接下来,Step3中使用RL来优化原始语言模型,以便与奖励模型相协调。
用
这里
奖励模型的训练
不同大小模型的使用:
成功的RLHF系统到目前为止使用了与文章生成(例如,OpenAI的175B语言模型,6B奖励模型)相对大小不同的奖励语言模型。
奖励模型可能是另一个微调过的语言模型或从偏好资料上从头训练出的模型。
Anthropic通过专门的微调方法来初始化这些模型(preference model pretraining, PMP),这被认为比一般的微调方法更有效率。
生成资料集The training dataset of prompt-generation pairs for the RM:
从预定义的资料集中抽样一组提示(Prompts)。
这些提示通过初始语言模型(Initial Language Model)来生成新文章。
Anthropic主要使用Amazon Mechanical Turk的聊天工具来生成数据,而OpenAI则使用GPT API用户提交的提示。
人类评分:
用人类评注者对语言模型生成的文章输出进行排名。
使用排名而不是直接的标量评分,以减少不同人类价值观造成的校准问题和噪音。
排名方法:
使用比较两个语言模型在相同提示下生成的文章的方法。
透过头对头比较,使用Elo系统对模型和输出相对于彼此进行排名。
将不同的排名方式转换成一个数字(标准化为0-1),作为训练时对模型的奖励指标。
在这个阶段,拥有一个初始的语言模型(Initial Language Model)用来生成文字,还有一个偏好模型(Reward Model),它可以将任意的文字评分,衡量人们对其的感知好坏程度。下个步骤将使用强化学习(RL)来优化初始语言模型,使其根据Reward Model得到更好的表现。
Step3. Fine-tuning with RL
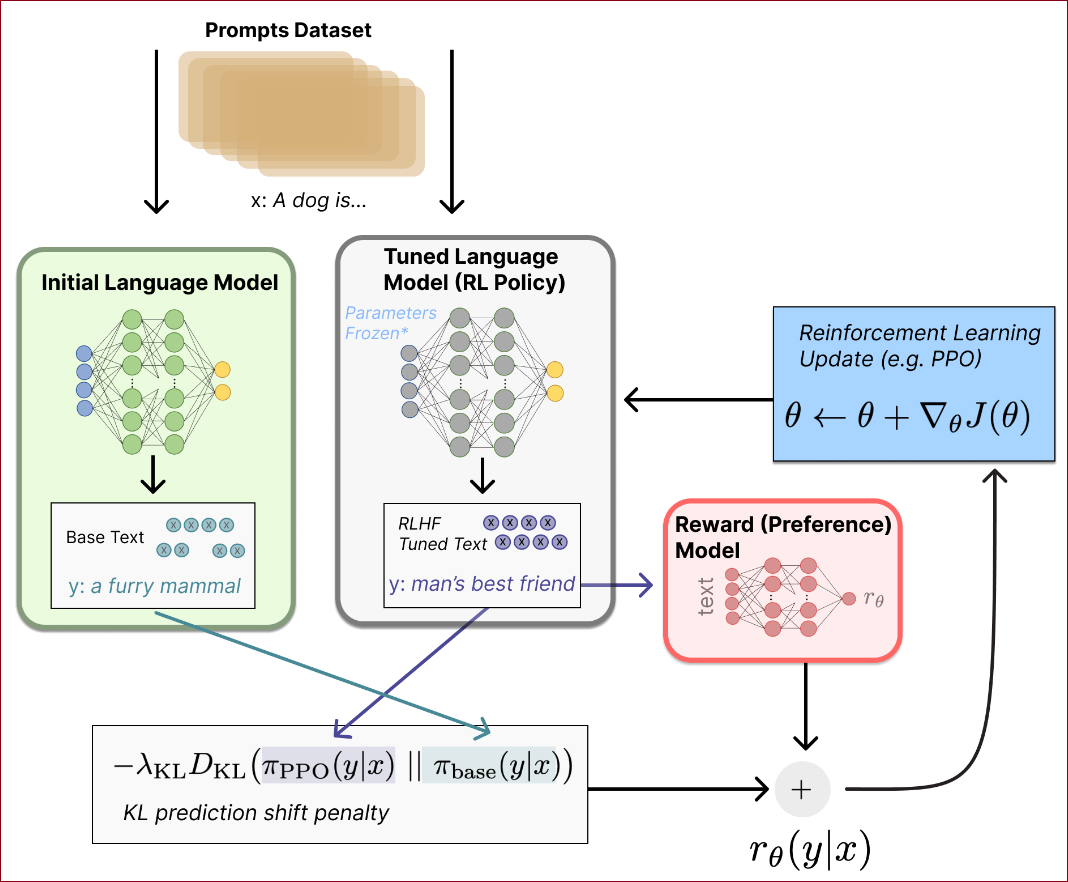
强化学习(RL)对语言模型(LM)进行微调的过程简要
资料集提示:从提示资料集中取出一个提示
,例如:“狗是...”。 初始语言模型:这个模型产生基础文章
,例如:“a furry mamal”。 调整语言模型(RL策略):经过RL微调的模型根据相同的提示生成调整过的文章,例如:“man's best friend”。
奖励(偏好)模型:评估调整过的文章并返回一个标量的“偏好度”
。 KL预测偏移惩罚:计算RL策略生成的每个token的概率分布与初始模型的概率分布之间的Kullback-Leibler(KL)散度
,这个散度(比对两个概率分布是否接近)作为惩罚项,防止RL策略与初始预训练模型相比有太大的偏移。 强化学习更新:使用策略优化演算法(目前主流是Proximal Policy Optimization, PPO)更新模型的参数
,按照梯度 来更新奖励函数走向。 技术说明:尽管图表看起来两个模型为相同的提示生成不同的回应,但实际上是RL遵循策略生成文章,然后将这些文章送入初始化模型以产生用于KL惩罚的相对概率。在训练过程中,这个初始模型不会受到梯度更新的影响。
从RL任务说明步骤:
策略(policy):是一个语言模型,它接收一个提示并返回文章序列或者文章上的概率分布。
行动空间(action space):策略的行动空间是对应于语言模型词汇库的所有token(通常是50k左右的token)。
观察空间(observation space):观察空间是可能的输入token序列的分布,由于前面使用的RL,这也是相当大的(维度大约是词汇库大小的长度次方)。
奖励函数(reward function):奖励函数是偏好模型与策略转移限制(Policy shift constraint)的结合。
reward function系统细节:奖励函数在强化学习中扮演了将不同模型整合入单一RLHF过程的角色。以下是该过程的关键概念和步骤:
生成文章:给定资料集中的一个提示 x ,经过微调策略的当前迭代生成文章 y;
偏好模型评分:将生成的文章与原始提示串联后传递给偏好模型,它返回一个表示“偏好度”的标量值 r_\theta(y|x)。
KL惩罚:将RL策略的每个token的概率分布与初始模型的概率分布进行比较,计算她们之间差异的惩罚。这个惩罚通过Kullback-Leibler(KL)散度
总奖励计算:最终发送到RL更新规则的奖励计算如下:
其中,
额外奖励条款:一些RLHF系统在奖励函数中添加了额外的条款,例如OpenAI在InstructGPT上混合了额外的预训练梯度(来自人类注释集)进入PPO的更新规则。
更新规则:PPO的更新规则是根据当前资料批次最大化奖励指标的参数更新(PPO是一种on-policy算法,意味着参数仅用当前批次的提示-生成对更新)。PPO是一种新信赖域优化算法,它使用梯度上的限制以确保更新步骤不会破坏学习过程。DeepMind对Gopher使用了类似的奖励设置,但使用了同步优势演员-评判(synchronous advantage actor-critic, A2C)来优化梯度,这有显著的不同,但尚未在外部重现。
个人补充(博文3) - LM参数更新
初始语言模型(initial Language Model)的参数在RL微调过程中是固定的
被微调的语言模型(Tuned Language Model,也被称为RL Policy)的参数会根据强化学习更新(例如使用PPO算法),注意Tuned LM中的大部分参数颜色被标记为冻结“Frozen”,即这些参数在微调过程中保持不变。只有模型的输出层或者特定的可训练层进行更新。
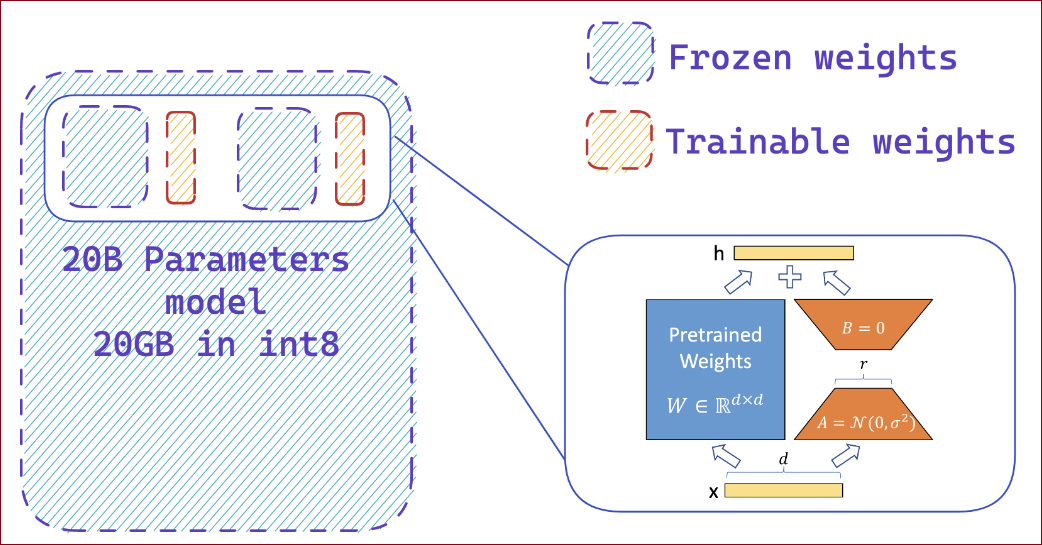
在实际应用中,可能会使用或结合Parameter-efficent fine-tuning(PEFT)参数高效的微调方法,如LoRA(Low-Rank Adaptation)、Adapter等来进行微调?
答案:是的!参见这里。
开源工具 for RLHF
Implicit Language Q-Learning, ILQL. 值得关注的新RL算法。
算法 Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
Demo RLHF+PEFT
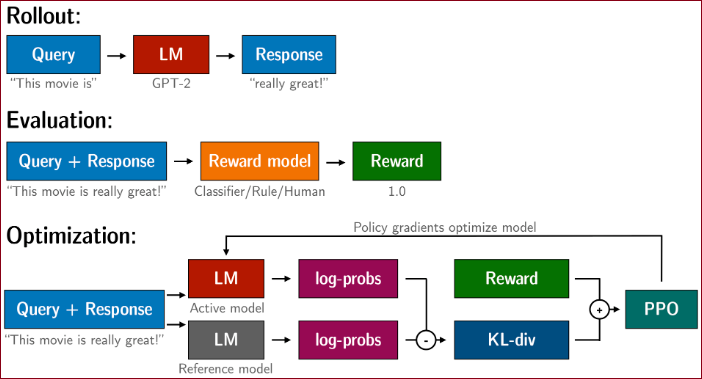
Overview of the PPO training setup in TRL.
Step2. Add extra trainable adapters using PEFT
算法The Full Story of Large Language Models and RLHF
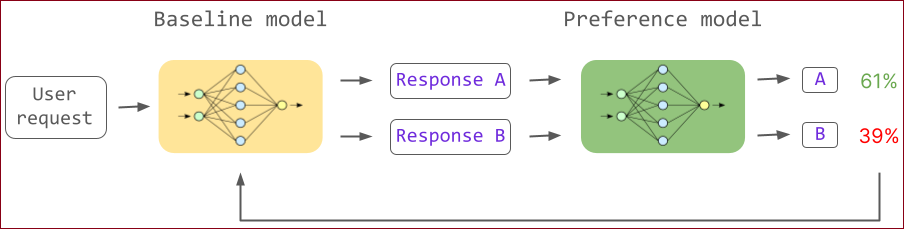
What RLHF actually does to an LLM
这边从概率分布匹配的观点来解释RLHF对LLM的微调如何对齐人类的意图
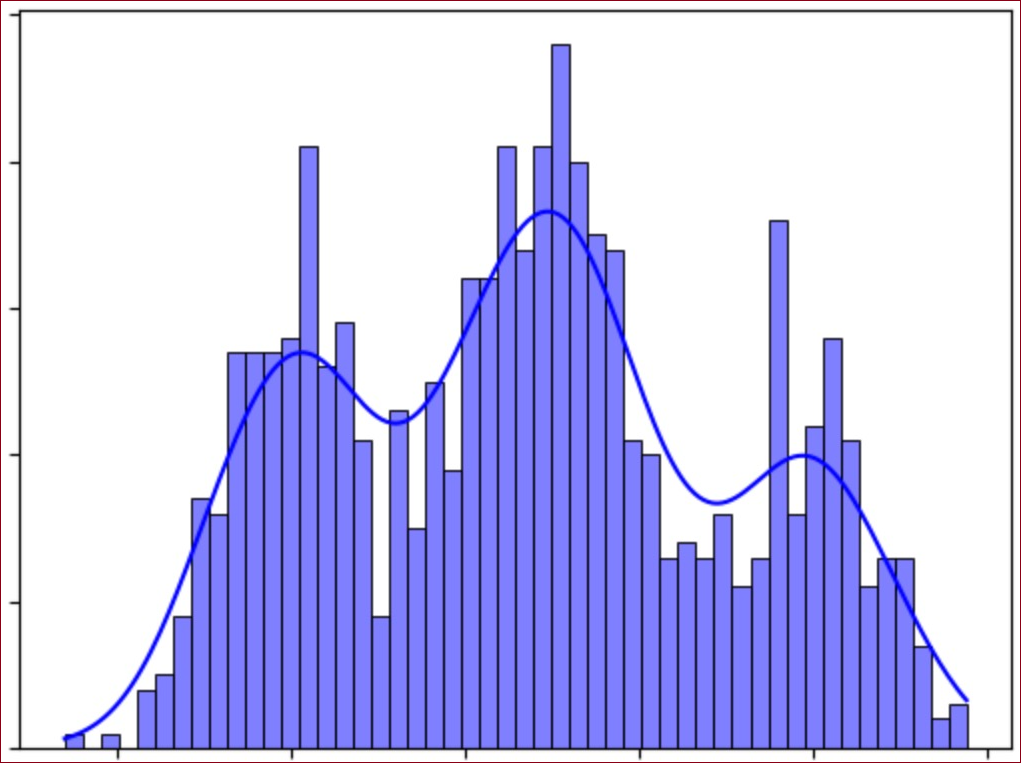
A multimodal distribution with three modes or “peaks”. The base model is trained to approximate the distribution of internet text, which has millions of different modes corresponding to different sources, styles, and voices.
图中可以看到一个具有三个模式或“峰值”的多模态分布。基础模型(Base Model)被训练来近似互联网文章的分布,这个分布有数百万不同的模式,对应于不同的来源、风格和声音。
RLHF对于“纯粹”的基础大型语言模型(LLM)的微调实际上是这样一个过程:
分布匹配:理想的基础模型可以完美地复制互联网文章的高度多模态分布,这意味着它成功地完成了分布匹配任务。
输出的不确定性:然而,在推理时,这样的理想模型可能会展现出一种不稳定性,即在选择数百万模式中的哪一个时,可能会有所波动。
例如,当用户提出有关某著名政治人物的查询时,模型可能产生一个模仿中立、资讯性维基百科文章调调的输出(可以说它选择了分布中的百科全书模式)。相反地,根据问题的措词,模型可能会被诱导采用一种更极端的观点,这种观点是受到互联网上遇到的激进观点的启发。
在基础模型预测在分布中两种不同模式之间的数值估计只有细微差异的情况下,应该选择哪种模式?完全依赖模型的随机决策性质不是理想的解决方案。
以概率模型来理解RLHF
当我们有一个理想的基础大语言模型(LLM),它能够完美地复制互联网文章的分布,我们可以用一个多模态概率分布来形象化这个情况,记为
假设在这个分布中有两个明显的模式
在一个多模态分布中,模型产生输出的过程可以看作是从这个分布中抽样。如果模型在
这就是RLHF微调的用武之地。RLHF将人类的反馈引入模型训练过程,这可以被视为在原有的多模态分布
在数学上,这种偏好可以通过修正概率分布来实现,例如通过在原始分布上应用一个修正因子
其中
在这个框架下,
这样,RLHF就能够细致地调整LLM的行为,使其更好地符合人类的期望和偏好。这是一个动态过程,通过不断地从人类的互动中学习,模型能够逐渐改进其对复杂和多样化人类语言的模拟和生成能力。
过去几年里,以chatGPT为代表的基于prompt范式的大型语言模型 (Large Language Model,LLM) 取得了巨大的成功。然而,对生成结果的评估是主观和依赖上下文的,这些结果难以用现有的基于规则的文章生成指标 (如 BLUE 和 ROUGE) 来衡量。除了评估指标,现有的模型通常以预测下一个单词的方式和简单的损失函数 (如交叉熵) 来建模,没有显式地引入人的偏好和主观意见。
因此,训练阶段,如果直接用人的偏好(或者说人的反馈)来对模型整体的输出结果计算reward或loss,显然是要比上面传统的“给定上下文,预测下一个词”的损失函数合理的多。基于这个思想,便引出了本文要讨论的对象——RLHF(Reinforcement Learning from Human Feedback):即使用强化学习的方法,利用人类反馈信号直接优化语言模型。
--->还有很多,请看原文博文3
补充
head-to-head matchups, an Elo system 头对头比较与Elo系统
Elo系统是一种用来评估玩家或模型相对实力的排名系统,最初被用于国际象棋,但后来被广泛应用于其他领域,包括作为机器学习模型评估的一部分。 Elo系统的核心是一个数学模型,它赋予每个参与者一个数值排名,表示其实力水平。当两个参与者进行比赛时,系统会根据比赛结果来调整它们的排名。
在RLHF(Reinforcement Learning from Human Feedback)的上下文中,头对头比较和Elo系统可以帮助决定哪些模型生成的文章更能符合人类偏好。具体步骤如下:
初始排名:每个语言模型开始时都被分配一个初始Elo排名。
生成文章:每个模型根据相同的提示生成文章。
头对头比较:将两个模型生成的文章进行比较。这通常是通过人类评审来完成,他们会选择他们更偏好的文章。
更新排名:根据头对头比较的结果,使用Elo系统更新模型的排名。如果一个模型的输出(文章)被选择,那么该模型的排名将上升;如果没被选择,则下降。
计算新排名:Elo排名的更新是通过以下公式进行的:
其中:
在这里,
通过这种方法,每次比较后,模型的Elo排名将更加精确地反映其生成文章的质量。这样,Elo排名可以作为奖励模型训练中标量奖励信号的一部分。
想法
博文1
OpenAI 早期工作,思路流程和最新的RLHF流程已经很接近了,论文中并没有现在看起来惊艳的精度,不过提供了一个基于人类反馈进行微调的方案雏形;
本文总结的未来挑战
在线收集数据困难
工程实现复杂度高,需要支持数据收集,奖励模型训练,强化学习训练的分布式进行;整个流程中一个环节出现bug也会导致系统的崩溃
机器学习复杂度:在线系统debug困难。通常只能通过短暂地切换到脱机状态来调试在线作业;
数据质量控制;
奖励模型和强化学习policy模型共享参数会过拟合,无法作为多任务进行训练。多任务训练有很多优势,比如它可以帮助奖励模式保持足够强大,使policy模型无法投机取巧。共享还可以提高计算效率,允许模型共享激活,而不是需要两个单独的向前传递。
标注难度大:很多语言回答难以区分优劣,使得数据中噪声很多。
参考博文
Fine-Tuning Language Models from Human Preferences
点评:★★★☆☆ 文档相对较长,但是文字太多,实例略少,很多是了解型,大多数看完之后并不是很懂,还需要多看很多遍(同时结合其他博文吧...)
点评:★★★★☆ 文档对基础知识进行了介绍,重要的是,给定了一些案例,这个让我觉得很赞,所以必须四颗星。
Fine-Tuning Language Models from Human Preferences (RLHF)論文筆記-ChatGPT鍊成術
点评:★★★☆☆ 老实说,这个文档写的挺多的,但是也可能是我自己的原因,只顾在对内容进行整理和分类,没有深入去看其中的内容,但是有几点还是要评论一下,首先是台湾同胞写的,所以,用了中文繁体字,看起来比较麻烦,比如概率分布(几率分布)。其次,整个文章的排版和缩进无法区分具体的模块,导致不理解、没背景知识的人会很难捕捉到知识点所属类别。总的来说,文字多并不是一篇好文章的标准,重要的是能把概念讲清楚才算好。 这篇文章主要讲的是奖励模型相关内容,还是值得好好琢磨的。为微调提供了另一个思路或者说拓展了另一个思路。
引申可看
GPT3.5 - 论文精读学习笔记背景RLHF在LLM时代的重要性和亮点引言全文梗概摘要解读本文方案预训练模型细节微调细节数据集在线数据采集实验结果参考与补充开源工具 for RLHF补充想法参考博文原文目录
原文目录
1 Introduction 1 2 Methods 2 2.1 Pretraining details 3 2.2 Fine-tuning details 3 2.3 Online data collection 4 2.4 Human labeling 4 3 Experiments 4 3.1 Stylistic continuation tasks 5 3.1.1 Mock sentiment task 5 3.1.2 Human evaluations of continuations 6 3.2 Summarization 7 3.2.1 What our models copy 9 4 Challenges 11 4.1 Online data collection is hard 11 4.2 Sharing parameters between reward model and policy causes overfitting 12 4.3 Ambiguous tasks make labeling hard 12 4.4 Bugs can optimize for bad behavior 12 5 Conclusion 13 A Instructions for labelers 16 A.1 Sentiment 16 A.2 Descriptiveness 16 A.3 Summarization: TL;DR 16 A.4 Summarization: CNN/DM 16 B Human labeling details 16 C Samples 17
博文免责声明
本条博文信息主要整合自网络,部分内容为自己的理解写出来的,如有断章截句导致不正确或因个人水平有限未能详尽正确描述的地方,敬请各位读者指正;
引用出处可能没有完全追溯到原始来源,如因此冒犯到原创作者,请联系本人更正/删除;
博文的发布主要用于自我学习,其次希望帮助到有共同疑惑的朋友。